Canlıların davranışlarını inceleyip, matematiksel olarak modelleyip, benzer yapay modellerin üretilmesine sibernetik denir. Eğitilebilir, adaptif ve kendi kendine organize olup öğrenebilen ve değerlendirme yapabilen yapay sinir ağları ile insan beyninin öğrenme yapısı modellenmeye çalışılmaktadır. Aynı insanda olduğu gibi yapay sinir ağları vasıtasıyla makinelerin eğitilmesi, öğrenmesi ve karar vermesi amaçlanmaktadır.
İnsandaki bir sinir hücresinin (nöron) yapısı şu şekildedir:

Akson (Axon): Çıkış darbelerinin üretildiği elektriksel aktif gövdedir ve gövde üzerinde iletim tek yönlüdür. Sistem çıkışıdır.
Dentritler (Dendrites): Diğer hücrelerden gelen işaretleri toplayan elektriksel anlamda pasif kollardır. Sistem girişidir.
Sinaps (Synapse): Hücrelerin aksonlarının diğer dentritlerle olan bağlantısını sağlar.
Miyelin Tabaka (Myelin Sheath): Yayılma hızına etki eden yalıtım malzemesidir.
Çekirdek (Nucleus): Akson boyunca işaretlerin periyodik olarak yeniden üretilmesini sağlar.
Aksonda taşınan işaret sinapslara kimyasal taşıyıcılar yardımıyla iletilmektedir. Stoplazma -85mV ile polarizedir. -40mV (Na+ içeri): uyarma (+) akıma yol açar. -90mV (K+ dışarı): bastırma (-) akıma yol açar. Yani belirli bir eşik gerilim değerinin üstünde iken hücre uyarılırken, diğer durumlarda hücre bastırılır. Σ Bu duruma göre çıkış işareti üretilmesine sinirsel hesaplama denir.
İnsandaki bir sinir hücresinin matematiksel modeli ise şu şekilde gösterilebilir:
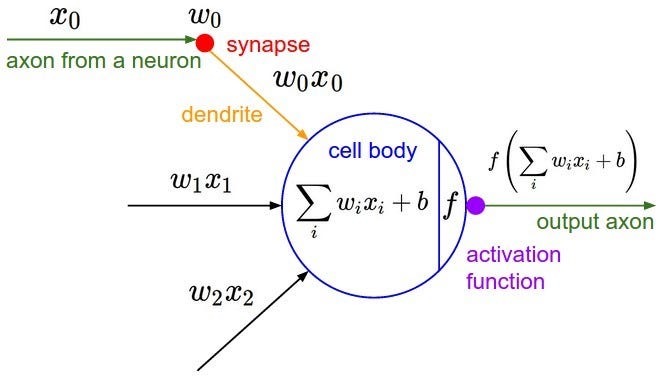
Perseptron (Perceptron): Yapay sinir ağının en küçük parçası olarak bilinen perceptron, aşağıdaki gibi lineer bir fonksiyonla ifade edilmektedir ve ilk defa 1957 yılında Frank Rosenblatt tarafından tanımlanmıştır.

y: x’in değerine bağlı olduğundan bağımlı değişkendir. Girdiye ait skoru verir.
x: bağımsız değişken, girdi.
W: ağırlık parametresi
b: bias değeri
YSA ya da Derin Öğrenme modelinde yapılan temel işlem; modelin en iyi skoru vereceği W ve b parametrelerinin hesabını yapmaktır.
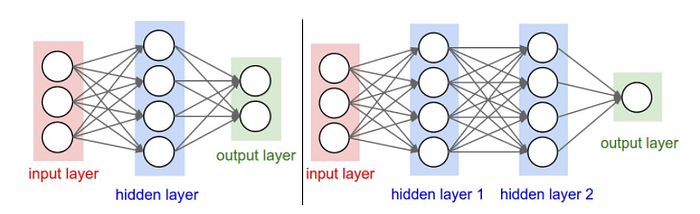
- Sol taraftaki tek katmanlı YSA modelinde 4+2=6 nöron bulunmaktadır (giriş katmanları hariç), [3×4]+[4×2]=20 ağırlık ve 4+2=6 bias değeri olmak üzere toplamda 26 adet öğrenilmesi gereken parametre vardır.
- Sağ taraftaki iki gizli katmanlı YSA ise modelinde 4+4+1=9 nöron, [3×4]+[4×4]+[4×1]=12+16+4=32 ağırlık ve 4+4+1=p bias değeri olmak üzere toplamda 41 adet öğrenilmesi gereken parametre vardır.
Tek katmanlı ve çok katmanlı YSA modelleri incelendiğinde önemli bir konunun ayrımına varmak gerekiyor. 1960 yılında Widrow ve Hoff çok katmanlı yapıya geçen ilk çalışmayı yapmışlardır.
Her Katmanın ve Her Katmandaki Nöronların Modele Etkisi/Katkısı Nedir?
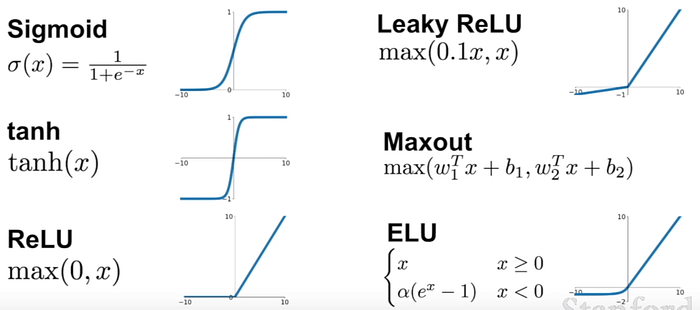
Bir katman içindeki nöronların birbirleriyle ilişkileri yoktur ve sistemde akılda kalan bilgiyi sonraki katmana ya da çıkışa aktarma işini gerçekleştirirler (her bir nöronun vazifesidir). Arka arkaya iki katmandaki nöronlar birbirlerini çeşitli aktivasyon değerleriyle etkilemekte ve modelin öğrenme seviyesini belirleyen bir aktarım gerçekleştirmektedir. Bu aktivasyon fonksiyonun nasıl seçilebileceği ve tam olarak çalışma mantığını anlattığım Derin Öğrenme İçin Aktivasyon Fonksiyonlarının Karşılaştırılması yazımı gözden geçirebilirsiniz.
O halde modelin bir katmanındaki nöron sayısı sistemin performansını dolaylı olarak etkilemektedir. ‘Katman sayısı arttıkça öğrenme performansı artar’, denebilir gibi görünse de bu doğru değildir. Çünkü model performansı, sadece girdiler ve katman sayısıyla ilgisi vardır ama bununla belirlenmez. Bir çok farklı hiperparametrenin etkisi çıkış performansını etkilemektedir. Model Girişin (x) ‘0’ olduğu durumlarda W.x=0 ve +b değeri skor fonksiyonunun çıktısını öteler. Böylece modelin bir sonraki iterasyonda öğrenme işlemine devam etmesini sağlar. Öğrenme işlemine yalnızca bu adımın etkisi yoktur. İleri ve geriye yayılım konularına da göz atınız. W ağırlık vektörü düğüm/nöron sayısı (hücre), bias (b) değerleri de gelecek katmandaki düğüm sayısı kadar olmalıdır.
Bir ağ modeli tasarlarken W ağırlık vektörünün değerlerini nasıl oluşturmalıyız?
Başlangıçta rastgele atanabileceği gibi geçmişte eğitilmiş bir modelin ağırlıkları giriş başlangıç ağırlıkları olarak tanımlanabilir. Ancak bu değerler atanırken (+) ya da (-) değerlerden rastgele dağılımlı olarak belirlenmelidir. Çünkü ‘0’ değeri verildiği durumlarda hesap katmanlarda sürekli aynı çıkacağından öğrenme gerçekleşmemiş olacaktır. Bu istenmeyen bir durumdur.
XOR problemi gibi tek katmanlı modelle çözülemeyen problemlerde bazı optimizasyon fonksiyonları tasarlanarak çözümü kolaylaştırmak mümkündür.
Başarılı şekilde tasarlanmış bir ağ modelinin başarımını belirleyen Kayıp/Yitim fonksiyonu (Loss function) değeri çeşitli optimizasyon teknikleriyle ‘0’a yaklaşması istenen bir fonksiyondur. Burada eğitim ve test gruplarının karşılaştırılmasıyla hesaplanan bir değerden söz ediyoruz. Ancak bu iki farklı kısıtla karşılaşmamıza sebep olmaktadır:
- Modeldeki tüm bilgileri kullandığımızda elimizde büyük boyutlu bir parametre bilgisi olur.
- Test işlemini yaparken eğitim setindeki tüm verilerle karşılaştırılma yapıldığında bu işlem yükünü artırır ve tespit süresini uzatır.
Bu iki durumun verimli bir ağ modelinde olmaması gerekir. Basit bir çözümle üstesinden gelinebilir. Test verileri eğitim verilerinden oluşan bir temsil grubuyla karşılaştırılır. Böylece işlem yükünün azalması sistemin hız bakımından performans kazanmasını sağlamaktadır. Burada önemli olan temsil verisinin nasıl seçildiğidir.

Eğitim verisinin içeriğindeki tüm bilgileri temsil eden bir veri elde etmek gerekmektedir. Bunun için öğrenme işleminden sonra ilgili verinin ağırlık matrisi (ortalaması) temsil verisi olarak alınmaktadır.
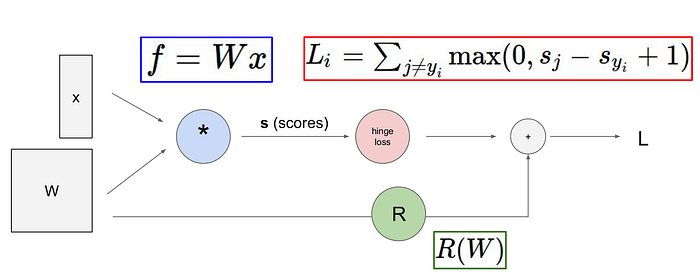
Loss değerine eklenen Regularizasyon (R) değerinden dolayı Loss hiçbir zaman sıfır olmayacaktır. W ağırlık vektörünün sıfır olduğu durumlar haricinde geçerlidir.
Regularizasyon sayısı kullanılması zorunlu omayan bir hiperparametredir. Kullanılması tavsiye edilir çünkü derin öğrenme başarımına pozitif yönde katkı sağlamaktadır. Loss hesabı yapılırken çeşitli optimizasyon teknikleri kullanılabilir. İki sınıflı basit bir problem için ‘Sigmoid’, daha kompleks sınıflandırma problemlerinde SVM’de s(f(W,x)) skor fonksiyonu ve model tarafından üretilen skor değerlini baz alarak olasılıksal olarak yitim hesabı yapar. Loglike değerini maksimize ve negatif olabilirlik değerini minimize etmek esastır. Bu işlemleri yaparken olasılık değerlerini en büyük olabilirlik yöntemiyle (maximum likelihood method) dönüştürme işlemi yapmaktadır. Yitim fonksiyonunun parçalı-doğrusal bir matematiksel yapıda olduğu anlaşılmaktadır.
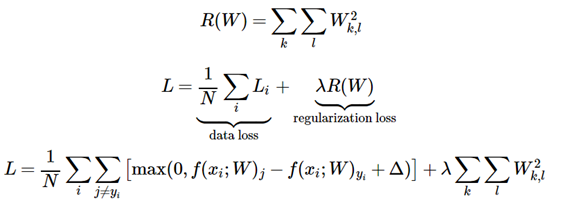
O halde SVM ya da Softmax kullanacağımıza nasıl karar vermeliyiz?
SVM (Support vector Machines-Destek Vektör Makineleri), benzerlik skoru üretirken Softmax benzerlikle ilgili olasılık değerleri üretir ve sonuç üzerinde normalizasyon yaparak olasılıksal hale dönüştürür. Bu sayede sınıflar arasındaki fark daha kolay yorumlanabilir bir hal alır. Sınıflandırma problemlerinde tercih edilmesi tavsiye edilir. Sistemin performansı açısından karşılaştırıldığında fark azdır. Aşağıda SVM ve Softmax için yitim hesabı gösterilmektedir.
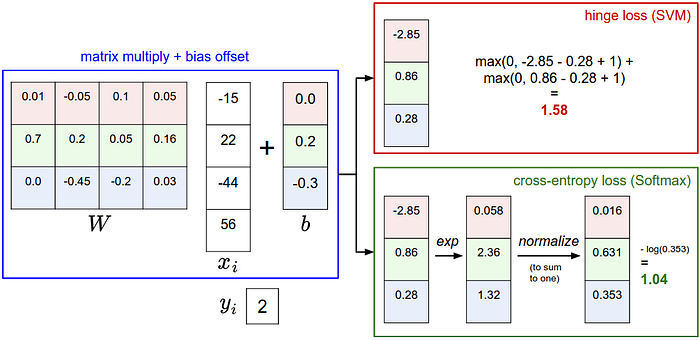
Daha detaylı bilgi için. http://cs231n.github.io/linear-classify/
Aşağıdaki demoyu kullanarak doğrusal sınıflama için parametreleri değiştirerek hesaplama sonucunda sınıflandırma performansını inceleyebilirsiniz.
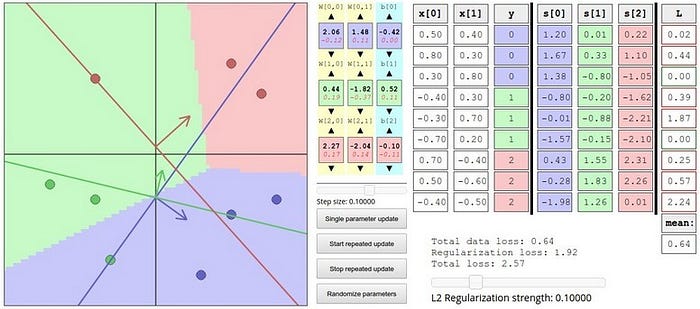
Loss fonksiyonunda minimumu bulmak için 3 farklı strateji geliştirebiliriz.
- Rastgele Arama (Random Search) (çözüm için en kötü fikir)
- Rastgele Yerel Arama (Local Random Search)
- Gradyan İnişi Takip Etme (Following Gradient Descent)
Bunların içinden Stokastik Gradyan İniş (Stochastic Gradient Descent-SGD) optimizasyonda en çok kullanılan yöntemlerin başında gelmektedir. İki şekilde gradyan hesabı yapılabilir.
- Numerik Gradyan: yavaştır, yakınsaklığı çok iyi değildir fakat programlaması kolaydır.
- Analitik Gradyan: hızlıdır, yakınsaklığı iyidir fakat hataya meyillidir.
Pratikte, analitik gradyan ile işe başlanır ve uygulama numerik gradyanla kontrol edilir.
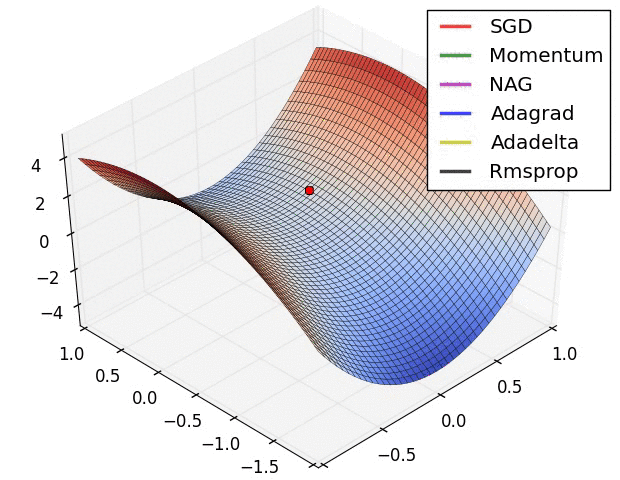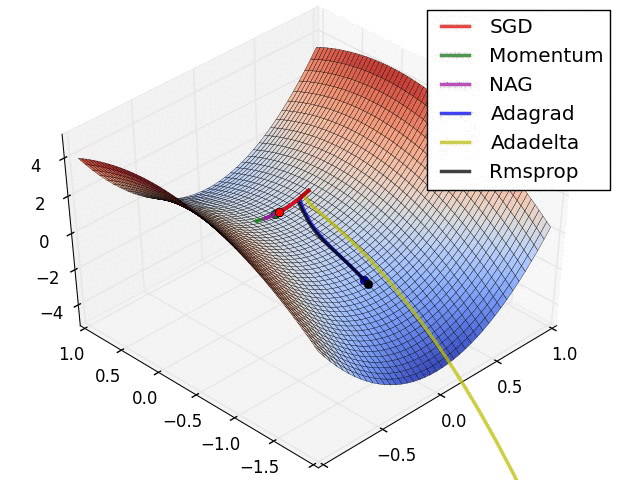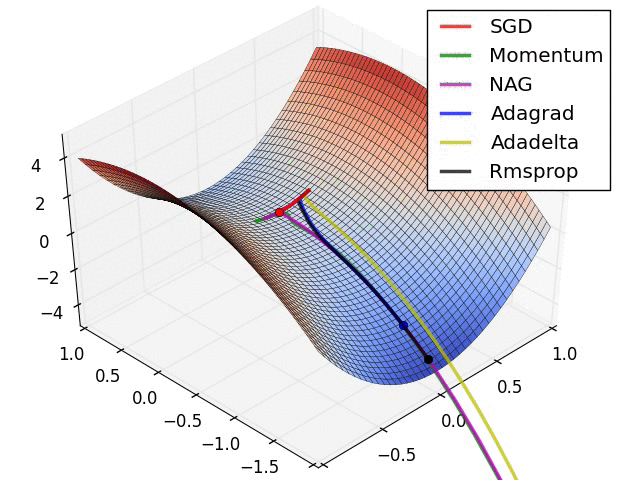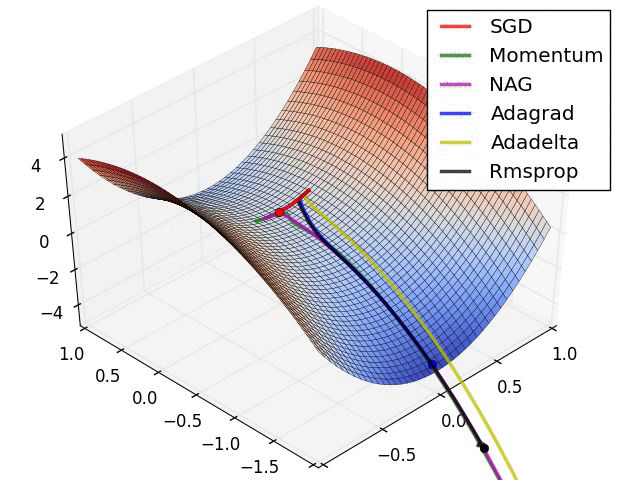
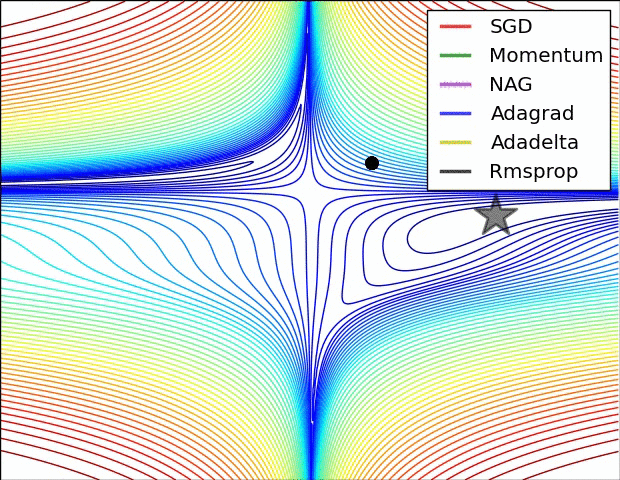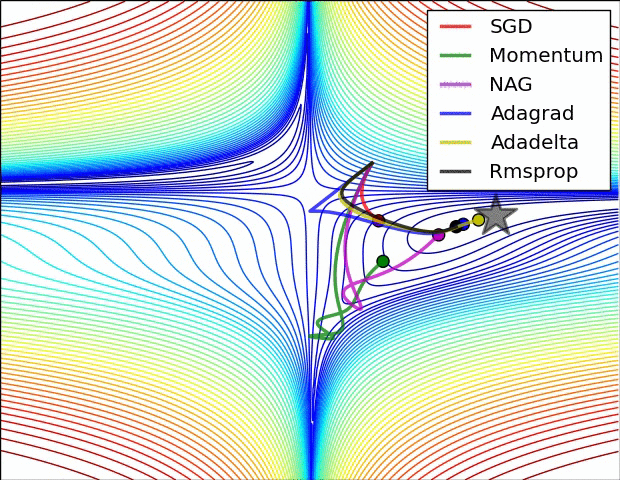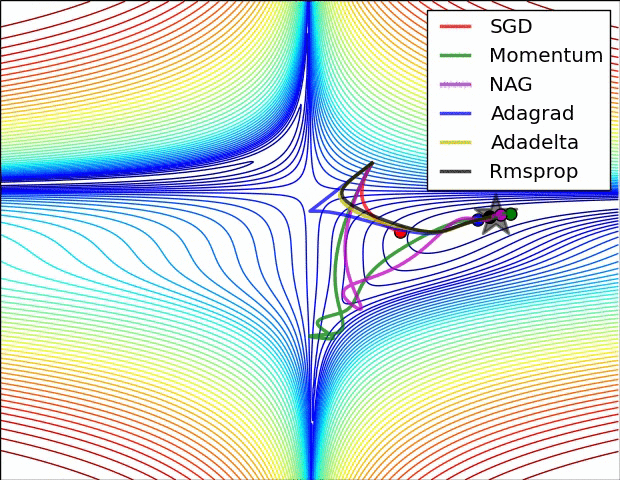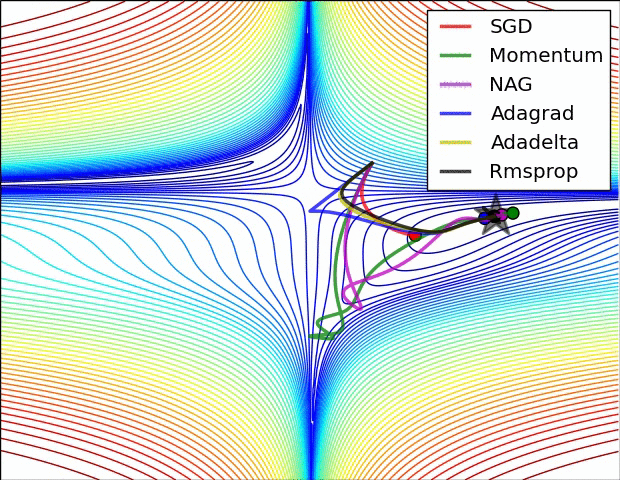
Başarımı artrımak için: Geriye Yayılım (Backpropagation)
1986 yılında Rumelhart ve arkadaşları tarafından kullandığında popülerlik kazanmıştır. Gizli katman ve çıkış katmanlardaki tüm ağırlıklar hesaba katılır. Hata miktarı gizli katmanlarda bulunan nöronlara geri dönerek modelin başarımı artırılmaktadır. Aslında Gradyan İniş algoritmasının YSA’daki adıdır. Giriş değerleri ağırlık katsayılarıyla çarpılarak gizli katman çıkışından modelin çıkışına aktarılır. Bu zaten ileri yayılımdır. Geri yayılım sayesinde modelin ağırlık katsayıları güncellenir ve model optimize edilmiş olur.
Aşağıdaki 2 girişli (x0, x1) nöron modeli aktivasyon olarak sigmoid fonksiyonu kullanmaktadır. Öğrenme için ağırlık katsayıları (w0, w1, w2) olarak gösterilmektedir.
Ağ modeli bu denklemden hareketle oluşturulmuştur. İleri yayılımda girişteki 2.00, -1.00, -3.00, -2.00,-3.00 değerleri ilgili işlemleri ileri yönde yaparak çıkışta 0.73 değeri adım adım elde edilmektedir.
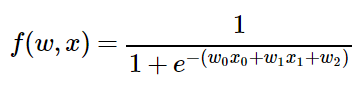
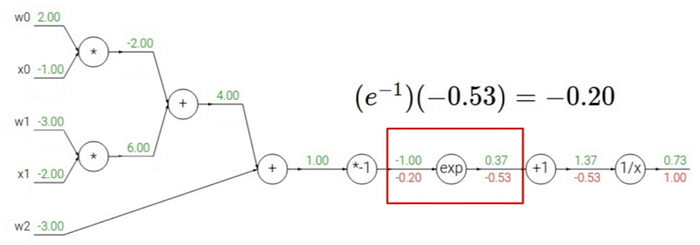
Geriye yayılımı gerçekleştirirken model içinde yer alan fonksiyonların gradyanlarını hesaplamak gerekir. Birinci adım için ilgili gradyan fonksiyonu aşağıda işaretlenen gibidir. 0.73 çıktısından geriye doğru işlemlerin nasıl gerçekleştiğine bakarsak:


Bir sonraki adımda yine ilgili gradyan işlemine göre işlem yapıldığında (1)(-0.53)=0.53 olarak yeni adım hesaplanmış olur.
Bir sonraki adımda yukarıda belirtilen ilgili türev sonucuna göre geriye doğru ağırlık güncellemesi aşağıdaki işlemle yapılır.
Bir adım daha işlem yapılırsa;

Yeni adımda artık toplama düğümden iki kola ayrılmak gerekmektedir. Her iki çıkış ağırlıkları hesaplanırken yerel gradyan ile ileri yöndeki gradyan değeri kullanılır. Sonuç aşağıdaki gibi bulunur.
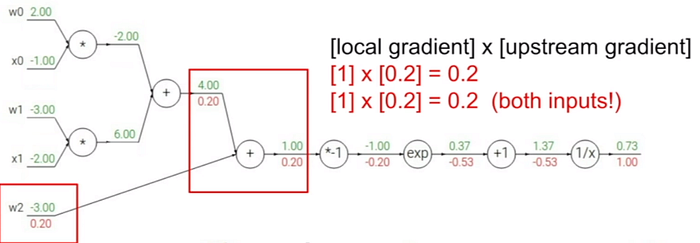
Çarpım düğümündeki işleme göz atarsak; x0 ve w0 değerlerini çarpma düğümüne gelen yeni ağırlıkla çarpmak gerekir.
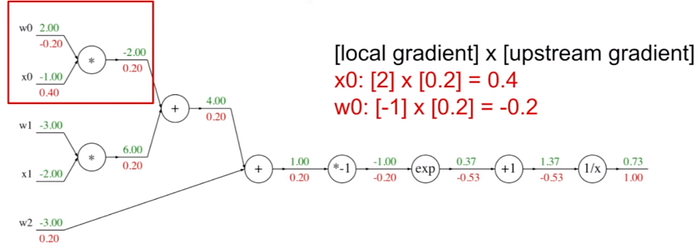
Böylece tüm ağ modelinde geriye doğru ağırlıklar güncellendiğinde elde edilen yeni ağırlıklar aşağıdaki gibi hesaplanmaktadır.
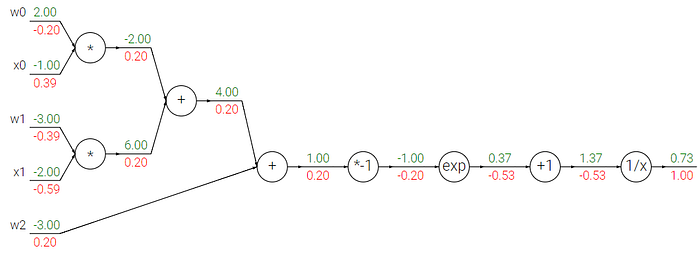
Modelin iki girişli kısımlarında yeni hesaplanan değer iki çıkışa da aktarılarak işlemler sürdürülür. Ayrıca bazı noktaların birleşimi bir başka modeli simgeleyebilmektedir. Örneğin aşağıdaki modelin bir kısmı sigmoid fonksiyonunu ifade etmektedir. Böylece modelin sonundan ilk dallanma düğümüne kadar olan kısmı tek adımda da hesaplayabiliriz.

Tüm adımların geriye doğru hesaplanması modelin optimizasyonu ve öğrenme işlemini gerçekleştirilmesi için çok önemlidir. Bilinmelidir ki YSA bir kapalı kutu değildir.
Bu şekilde iki katmanlı bir ağ modelinin eğitilmesi için 11 satırlık Python kodu yeterlidir.

Kaynak: http://iamtrask.github.io/2015/07/12/basic-python-network/
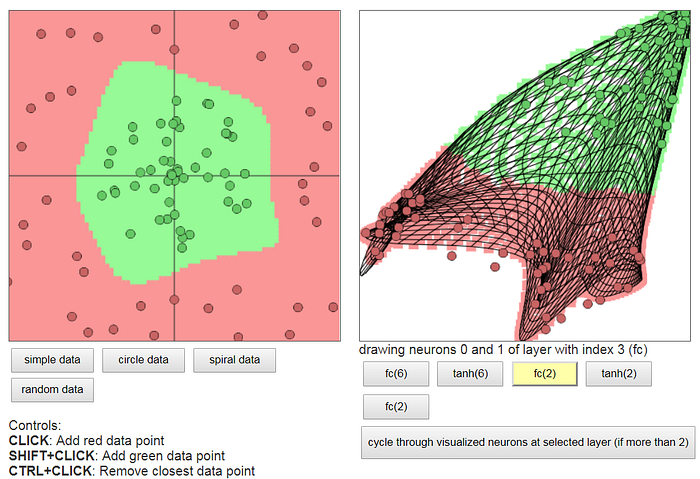
2 boyutlu bir sınıflandırma problemini 2 katmanlı bir sinir ağı modeliyle ve farklı aktivasyon fonksiyonlarıyla nasıl çözüme gidildiğini görsel olarak ta anlayabilmek için aşağıdaki linkteki demoyu çalıştırınız. Ağ modelini dilediğiniz gibi değiştirerek biraz oyun oynamanın tadını çıkarın! (Demo için görüntüye tıklayınız)
İnsan beyni ve sinir ağı yapısı gibi biyolojik bir esin kaynağıyla yola çıkılarak öğrenme, karar verme gibi problemlere YSA ile çözümler getirilmiştir. Kapalı kutu karmaşasını ortadan kaldırmak ağ modellerinin iç yapısı ve hesaplamaları incelemek konuyu anlamaya ve yeni çözümler üretmeye olanak sağlamaktadır.
1950’li yıllardan başlayan yapay sinir ağı çalışmaları, internet çağıyla birlikte biriken verilerin üstel olarak artması, mobil uygulamaların akıllı hale getirilmesi, tıbbi alandaki gelişmeler gibi ve bunlara bağlı olarak sistemlerin öğrenme, karar verme, akıl yürütme gibi işlevleri gerçekleştirmesi için standart YSA modellerinin yetersiz kalması farklı bakış açılarını beraberinde getirmiştir.
1998’de Yann LeCun ve arkadaşları tarafından LeNet mimarisi ile Evrişimsel Sinir Ağları (Convolutional Neural Networks-CNN) kullanarak, 2006 yılında Hinton ve Salakhutdinov “Reinvigorated research in Deep Learning” çalışmaları ile Sınırlı Boltzman Makinesi (Restricted Boltzman Machine-RBM) kullanarak, Derin Öğrenme konusunu popüler hale getirmişlerdir.
ayyucekizrak.medium.com